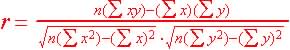General Statistics
Regression and Correlation
Learning Module
|
General Statistics |
Regression and Correlation Learning Module |
|
Linear Correlation Linear correlation coefficient is a statistical
parameter, r used to define the strength and nature of the
linear relationship between
The symbol for the sample correlation coefficient
is r. The symbol for the population correlation coefficient
is The correlation coefficient presented in this text is the Person's
product moment correlation coefficient (PPMC),
1. Know the meaning of the terms correlation and linear correlation. A correlation is when two or more variables are related in some way. Correlation requires that pairs of points be available for each set of values of each variable. Often in the case of two variables one may arbitrarily labeled each variable X and Y. Often the X variable represents the input variable or independent
variable, that is, the variable being used to predict the
A linear correlation is when two are more variables are related
linearly, i.e. A scattered plot of the data would tend to cluster
2. Know the meaning of high, moderate, low,
positive, and negative correlation,
and be able to recognize each from
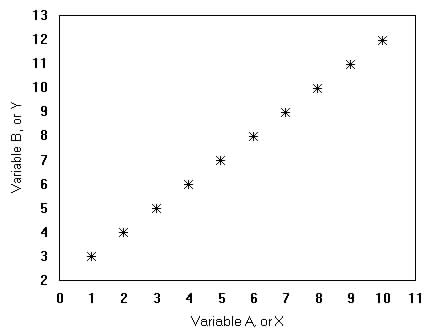
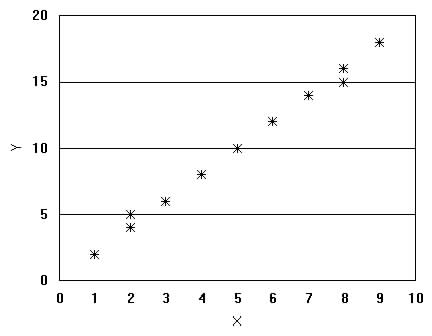
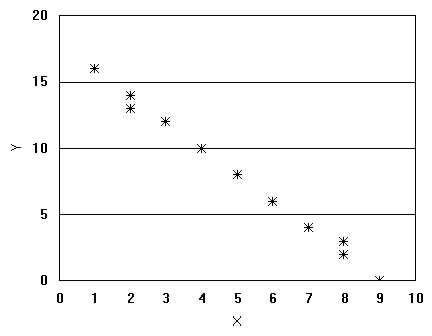
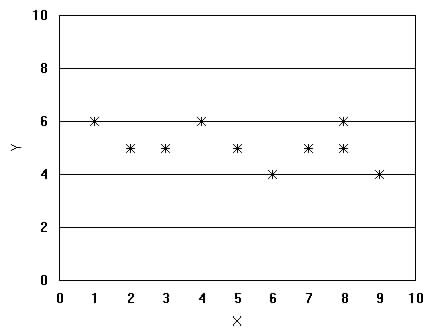
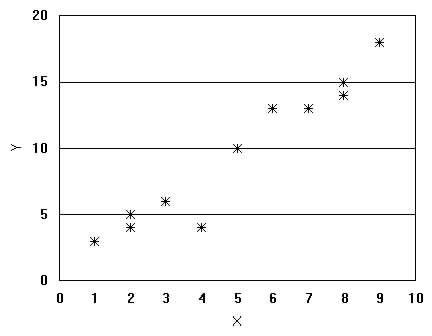
The number statistics used to describe linear relationships between two variables is called the correlation coefficient, r. Correlation is measured on a scale of -1 to +1,
where 0 indicates no correlation (Figure
3.2c) and either -1 or +1 suggest
High Correlation - if one variable can consistently predict
the value of the other variable, then a high degree of correlation
When two variables correlate and when the value of one increases
as the value of the other decreases we say the
Moderate correlation is often suggested by a correlation coefficient
of about 0.7. There is no absolute number guide for
A graph of the data may also show the degree of correlation between variables, see Figure 3.2 below. Figure 3.2 Graphs of Correlation Plots
3. Know how to calculate the correlation coefficient, r from a set of paired data. The correlation
coefficient, r show the degree of linear relationship between two variables.
So given pairs of values
Correlation coefficient, r computational formula:
Example: Compute the correlation
coefficient for the pairs of values for the two variables below:
Workshop
3a. Correlation Example: Calculate the Correlation Coefficient
of the following pairs of data:
4. Know the meaning of linear and nonlinear relationships and the relevance of each to correlation analysis. A linear relationship is one where a change in value of one
variable will have a consistent change in value of the
Figure 3.3a. A nonlinear relationship exist when the pairs of points of
both variables cannot be connected or approximated by
Figure 3.3 Linear and Nonlinear Relationships
5. Know the effect of changing units of X and / or Y on the correlation coefficient. Adding, subtracting, multiplying or dividing a constant to all of
the numbers in one or both variables do not change
6. Know the types of scale required for correlation analysis. Correlation analysis requires that both variables be measured at
least at the level. Simply for each values of X, Y is
7. Know the effect of the unreliability of the variables on the correlation coefficient. If values of either variable are unreliable (that is, they
have measurement or other errors) then the correlation coefficient
8. Know the effect of restricted or truncated range on the correlation coefficient. If either of the variables has a restricted range (not the
full
range of values of the population of interest) then the
9. Know the relationship between correlation and causation. High correlation between variables does not mean that one variable cause the other. High correlation just suggest that a causal relationship might exist. No correlation assume no causal relationship exists between two variables;
however, lack of correlation may be due
10. Know how to interpret a correlation coefficient,
r
in terms of (coefficient of determination)
The coefficient of determination, r2 is the square of the correlation coefficient, r The coefficient of determination is equal to the percent of variation
in one variable that is accounted for (predicted)
Though the correlation coefficient is useful to determine the degree
of linear relationship between tow variables,
The greater the proportion of explained variation, the closer are
the y values and y values, hence the stronger the
The simplest way to calculate the proportion of explained variation
over the total variation (coefficient
of determination, r2)
|
|
Linear Regression Linear regression is a methodology
used to find a formula that can be used to relate two variables that are
linearly related,
The regression formula found looks something like
this: y=mx+b, where
m and b are constants determined by the regression
1. Know the difference between correlation and regression analyses. Correlation analysis is concern with knowing whether there is a relationship between variables. Regression analysis is concern with finding a formula that
represents the relationship between variables so as to find an
2. Know how to interpret the equation of a linear regression formula, y=mx+b. A linear formula when graphed produced a straight line and is represented by the formula y=mx+b for variable X and Y. This linear formula is also called the regression line. The regression formula is used to predict values of one variable,
given values of another variable. Prediction can be made
The slope of a linear line is represented by the value of
m
in the regression formula above, and it is the rate of change of Y
If X and Y are plotted on a graph and the relationship
is approximately linear, a regression line or equation may be used
The point where the regression line crosses the Y axis is
called the y-intercept and is represented by b in the regression
formula.
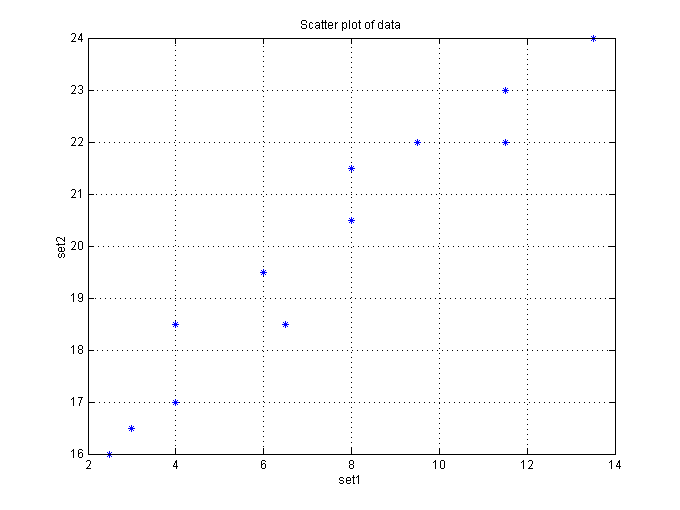
Figure 3.4 below shows a regression line with data scattered about the line (an estimate), where b=x, the slope, m = y. Example find the regression equation for the data in Table 3.4 below
using the online statistics tool
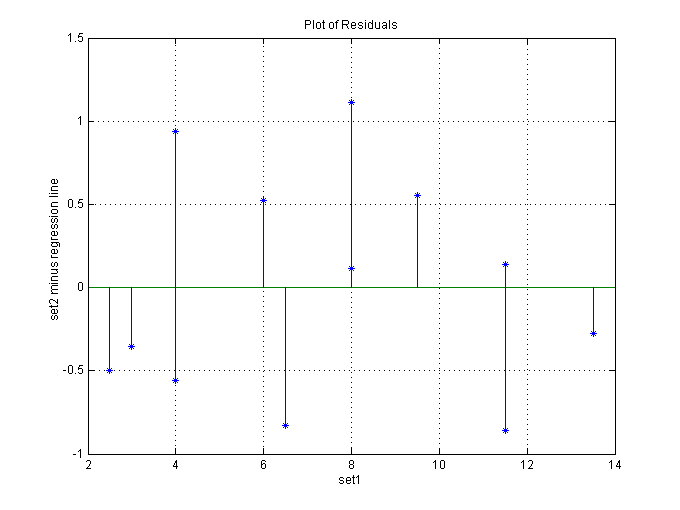
The regression formula is y = 14.7345 + 0.70666x, where 14.7345 is the y-intercept and 0.7067 is the slope. 3. Know the meaning of residual. The predicted value is the value of the Y variable that is
calculated from the regression line.
The residual is the difference of the actual value from the
predicted value:
Example (Using pervious example above)
Residual is the same as the error
of estimate, e, where e = y - Example when x = 6.5 above, y = 18.5 and the
predicted value, e = 18.5 - 19.35 - -0.85 4. Know how to determine linear relationship from a scattered plot. If the points in a scattered plot cluster about a non-horizontal
line (horizontal line has a zero slope),
above). 5. Know the meaning of the Least Square Criterion.
The line of best fit or regression line is the line
that best fits the data is the line in which the sum of squares for error,
6. Know the criteria used for forming the regression equation. The regression equation or formula meets the "least Square" criterion - the sum of square of the residual is at its minimum. 7. Know how to predict using the correlation coefficient and z-scores. A predicted z-score (for the Y variable) is equal to the correlation coefficient, r times the corresponding z-score for X. Example, if the z-score for a value of the X variable
is -1.12 and the correlation coefficient is 0.77, then the z-score for
Given (x, y): then z-score(y) = z-score(x) times correlation coefficient. 8. Know how to calculate the regression equation for a set of data using Least Square or best fit formulas: To find the parameters for a linear regression formula, y=mx+b.
Example Shows how this is done for a set of data: Table 3.5 Best fit calculation of regression line
There the slope is And So y=0.71x+14.71 Workshop
3b - Regression Example Using Least Square Formulas find
the best fit for the following data:
9. Know appropriate steps to take before computing a regression equation (line). Do not blindly compute the regression line, look first at scatterplot,
and investigate linearity with statistics
(a) Study Scattered plots (check for linearity) (b) Examine correlation coefficient or better yet the coefficient o f determination 10. Know the relationship of outliers or unusual observation on regression line. Unusual observations are point that seem to deviate for the clusting of the other points. An outliers is an observation that substantially affect or alter the regression line. When an unusual observation have a large influence on the regression line it is called an influential observation. Influential unusual observations that are identified as outliers
are not included in calculating the regression line.
|
|
Coefficient of Determination The coefficient of determination, r2
is another way of looking at the correlation coefficient, r,
it is the square of the
11. Know the meaning of total variation, unexplained variation, and explained variation. Given a set of data, its scatterplot and regression line, Total deviation (or variation) is
the sum of the squared deviation of each value from the mean of that variable.
For the variable,
Total deviation = Explained deviation + Unexplained deviation
Explained deviation or variation
is the sum of squared deviations of each predicted value from the variable's
mean:
Unexplained deviation or variance
is the sum of the squared deviations of each value of the variable from
its predicted value,
Table 3.6 Variation table (From Table 3.4)
12. Know how the coefficient
of determination, r2 can be computed from the total deviation
or variation
The coefficient of determination, r2, is the ratio of the
explained deviation over the total deviation.
Example; From Example in Table 3.6
13. Know the meaning of how to interpret the standard error of estimate. The standard error
of estimate,
The standard error of the estimate is an indication of the accuracy of the prediction or regression equation. If there is perfect prediction, the sum of residuals will be equal to 0 (similar to Figure 3.3a). If there is no prediction the standard error of the estimate will be the same as the standard deviation of Y. Residuals are assumed to be normally distributed for random collection
of data. So a plot of the residual should
The best fit or least square line attempt to fit a linear line
to the scattered plot of the data so as to minimize
14. Know common mistakes to avoid when using correlation and regression analyses. Avoid equating correlation with causality. Strong correlation between variables does not mean that one cause the other. Avoid unwarranted extrapolation of inferring or making predictions outside of the range of values of the variables studied. Example: If your study focused on students age 13 to 16, it might
be questionable using such results to
|